As machine learning technologies continue to advance, the need for high-quality data has become increasingly important. Data is the lifeblood of computer vision applications, as it provides the foundation for machine learning algorithms to learn and recognize patterns within images or video. Without high-quality data, computer vision models will not be able to effectively identify objects, recognize faces, or accurately track movements.
Machine learning algorithms require large amounts of data to learn and identify patterns, and this is especially true for computer vision, which deals with visual data. By providing annotated data that identifies objects within images and provides context around them, machine learning algorithms can more accurately detect and identify similar objects within new images.
Moreover, data is also essential in validating computer vision models. Once a model has been trained, it is important to test its accuracy and performance on new data. This requires additional labeled data to evaluate the model’s performance. Without this validation data, it is impossible to accurately determine the effectiveness of the model.
Data Requirement at multiple ML stage
Data is required at various stages in the development of computer vision systems.
Here are some key stages where data is required:
- Training: In the training phase, a large amount of labeled data is required to teach the machine learning algorithm to recognize patterns and make accurate predictions. The labeled data is used to train the algorithm to identify objects, faces, gestures, and other features in images or videos.
- Validation: Once the algorithm has been trained, it is essential to validate its performance on a separate set of labeled data. This helps to ensure that the algorithm has learned the appropriate features and can generalize well to new data.
- Testing: Testing is typically done on real-world data to assess the performance of the model in the field. This helps to identify any limitations or areas for improvement in the model and the data it was trained on.
- Re-training: After testing, the model may need to be re-trained with additional data or re-labeled data to address any issues or limitations discovered in the testing phase.

In addition to these key stages, data is also required for ongoing model maintenance and improvement. As new data becomes available, it can be used to refine and improve the performance of the model over time.
Types of Data used in ML model preparation
The team has to work on various types of data at each stage of model development.
Streamline, structured, and unstructured data are all important when creating computer vision models, as they can each provide valuable insights and information that can be used to train the model.
- Streamline data refers to data that is captured in real-time or near real-time from a single source. This can include data from sensors, cameras, or other monitoring devices that capture information about a particular environment or process.
- Structured data, on the other hand, refers to data that is organized in a specific format, such as a database or spreadsheet. This type of data can be easier to work with and analyze, as it is already formatted in a way that can be easily understood by the computer.
- Unstructured data includes any type of data that is not organized in a specific way, such as text, images, or video. This type of data can be more difficult to work with, but it can also provide valuable insights that may not be captured by structured data alone.
When creating a computer vision model, it is important to consider all three types of data in order to get a complete picture of the environment or process being analyzed. This can involve using a combination of sensors and cameras to capture streamline data, organizing structured data in a database or spreadsheet, and using machine learning algorithms to analyze and make sense of unstructured data such as images or text. By leveraging all three types of data, it is possible to create a more robust and accurate computer vision model.
Data Pipeline for machine learning
The data pipeline for machine learning involves a series of steps, starting from collecting raw data to deploying the final model. Each step is critical in ensuring the model is trained on high-quality data and performs well on new inputs in the real world.

Below is the description of the steps involved in a typical data pipeline for machine learning and computer vision:
- Data Collection: The first step is to collect raw data in the form of images or videos. This can be done through various sources such as publicly available datasets, web scraping, or data acquisition from hardware devices.
- Data Cleaning: The collected data often contains noise, missing values, or inconsistencies that can negatively affect the performance of the model. Hence, data cleaning is performed to remove any such issues and ensure the data is ready for annotation.
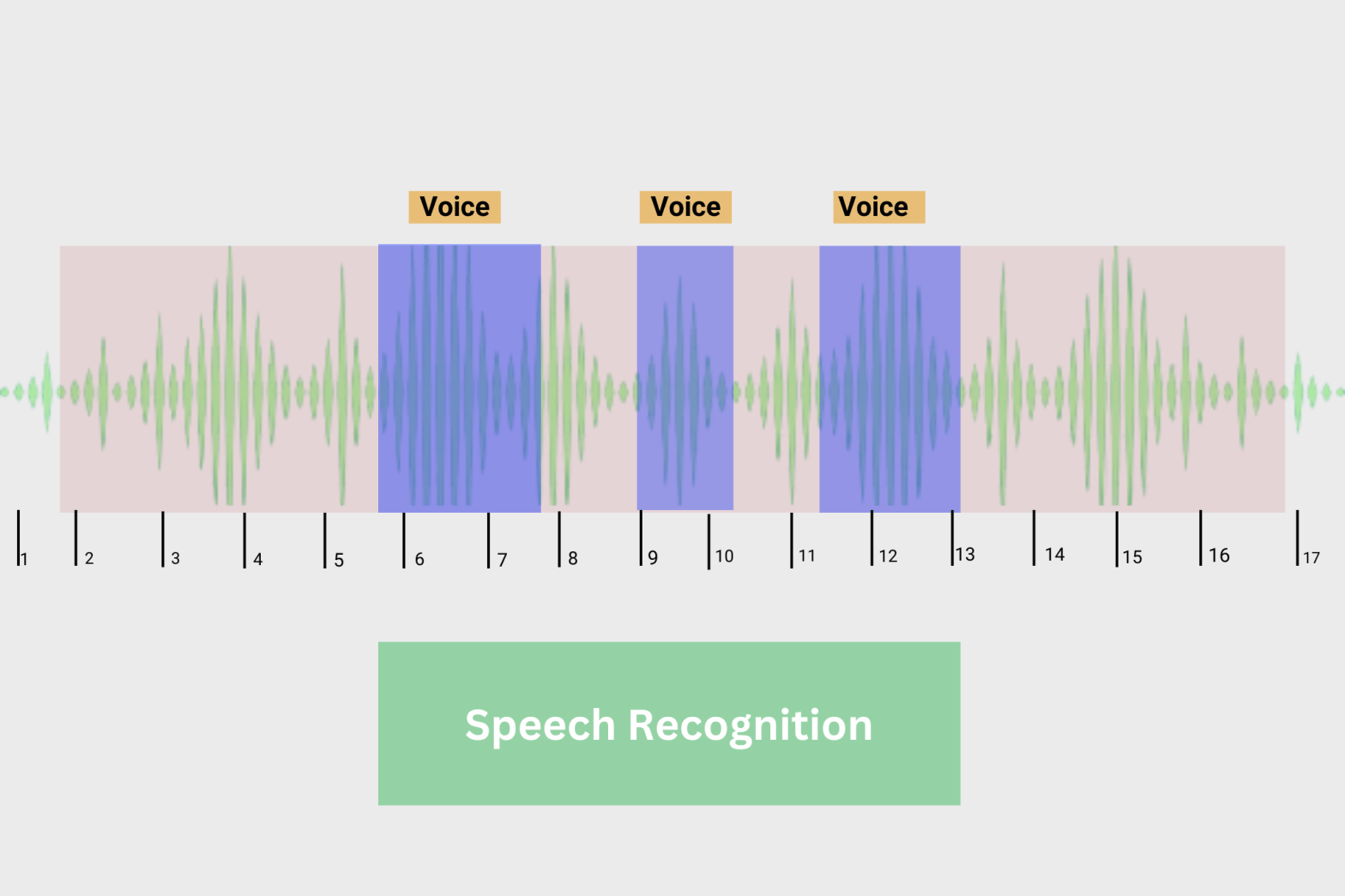
- Data Annotation: In this step, experts annotate the images with labels to make it easier for the model to learn from the data. Data annotation can be in the form of bounding boxes, polygons, or pixel-level segmentation masks.
- Data Augmentation: To increase the diversity of the data and prevent overfitting, data augmentation techniques are applied to the annotated data. These techniques include random cropping, flipping, rotation, and color jittering.
- Data Splitting: The annotated data is split into training, validation, and testing sets. The training set is used to train the model, the validation set is used to tune the hyperparameters and prevent overfitting, and the testing set is used to evaluate the final performance of the model.
- Model Training: The next step is to train the computer vision model using the annotated and augmented data. This involves selecting an appropriate architecture, loss function, and optimization algorithm, and tuning the hyperparameters to achieve the best performance.
- Model Evaluation: Once the model is trained, it is evaluated on the testing set to measure its performance. Metrics such as accuracy, precision, recall, and score are computed to assess the model’s performance.
- Model Deployment: The final step is to deploy the model in the production environment, where it can be used to solve real-world computer vision problems. This involves integrating the model into the target system and ensuring it can handle new inputs and operate in real time.
TagX Data as a Service
Data as a service (DaaS) refers to the provision of data by a company to other companies. TagX provides DaaS to AI companies by collecting, preparing, and annotating data that can be used to train and test AI models.
Here’s a more detailed explanation of how TagX provides DaaS to AI companies:
- Data Collection: TagX collects a wide range of data from various sources such as public data sets, proprietary data, and third-party providers. This data includes image, video, text, and audio data that can be used to train AI models for various use cases.
- Data Preparation: Once the data is collected, TagX prepares the data for use in AI models by cleaning, normalizing, and formatting the data. This ensures that the data is in a format that can be easily used by AI models.
- Data Annotation: TagX uses a team of annotators to label and tag the data, identifying specific attributes and features that will be used by the AI models. This includes image annotation, video annotation, text annotation, and audio annotation. This step is crucial for the training of AI models, as the models learn from the labeled data.
- Data Governance: TagX ensures that the data is properly managed and governed, including data privacy and security. We follow data governance best practices and regulations to ensure that the data provided is trustworthy and compliant with regulations.
- Data Monitoring: TagX continuously monitors the data and updates it as needed to ensure that it is relevant and up-to-date. This helps to ensure that the AI models trained using our data are accurate and reliable.
By providing data as a service, TagX makes it easy for AI companies to access high-quality, relevant data that can be used to train and test AI models. This helps AI companies to improve the speed, quality, and reliability of their models, and reduce the time and cost of developing AI systems. Additionally, by providing data that is properly annotated and managed, the AI models developed can be explainable and trustworthy, which can be beneficial for regulatory and ethical considerations.